Ever wondered what happens when everything suddenly stops working? That moment when lights go out, servers crash, or planes can’t take off? Welcome to the world of system failure—a silent but devastating force that can bring even the most advanced societies to their knees.
What Is System Failure? A Deep Dive into the Core Concept

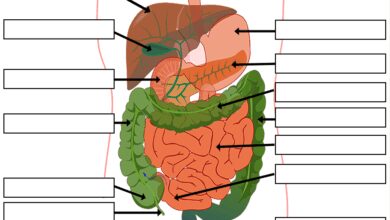
At its most basic level, a system failure occurs when a network, machine, software, or infrastructure stops functioning as intended. This isn’t just about a computer freezing—it’s about the collapse of interdependent components that rely on each other to maintain stability and performance.



Defining System Failure in Technical Terms
In engineering and systems theory, a system failure is defined as the inability of a system to perform its required functions within previously specified limits. This can be partial or total, temporary or permanent. According to the International Organization for Standardization (ISO), system failures are categorized based on severity, duration, and impact on safety and operations.
- Functional failure: The system no longer performs its intended task.
- Latent failure: A hidden flaw that only manifests under specific conditions.
- Cascading failure: One component’s failure triggers others to fail in sequence.
Types of Systems Prone to Failure
System failure isn’t limited to technology. It can occur in biological, ecological, economic, and social systems. For example:
- Technological systems: Power grids, cloud servers, AI algorithms.
- Biological systems: Organ failure, immune system collapse.
- Social systems: Government institutions, financial markets.
- Environmental systems: Climate feedback loops, ecosystem collapse.
“A system is only as strong as its weakest link.” — Often attributed to systems theorist Russell L. Ackoff.
Common Causes of System Failure Across Industries
Understanding why system failures happen is the first step toward preventing them. While causes vary by industry, several patterns emerge consistently across sectors—from aviation to healthcare to finance.
Human Error and Poor Decision-Making
One of the most frequent causes of system failure is human error. Whether it’s a misconfigured server, a misdiagnosed patient, or a poorly timed financial decision, humans remain the most unpredictable element in any system.
A well-documented case is the NASA Challenger disaster in 1986, where engineers’ warnings about O-ring failure in cold weather were ignored. The result? Catastrophic system failure 73 seconds after launch.
- Miscommunication between teams
- Lack of training or experience
- Overconfidence in automated systems
Software Bugs and Coding Errors
In the digital age, software underpins nearly every system we depend on. A single line of faulty code can trigger massive outages. In 2021, a typo in a configuration file caused a global Fastly CDN outage, taking down Amazon, Reddit, and the UK government website.
Common software-related system failure triggers include:
- Unpatched vulnerabilities
- Poorly tested updates
- Memory leaks and buffer overflows
Hardware Degradation and Obsolescence
Even the most robust hardware has a lifespan. Over time, components wear out, connections degrade, and systems become obsolete. The 2017 British Airways IT meltdown, which stranded 75,000 passengers, was traced to a single power supply unit that failed due to human error during maintenance.
Key risks include:
- Power surges damaging servers
- Aging data centers with outdated cooling systems
- Lack of redundancy in critical infrastructure
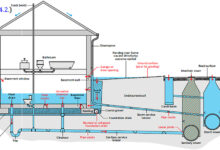
System Failure in Critical Infrastructure: Power Grids and Water Supply
When system failure strikes essential services like electricity and clean water, the consequences are immediate and life-threatening. These systems are designed with redundancy, yet they remain vulnerable to both natural and human-made threats.
Power Grid Collapse: The Domino Effect
Power grids are complex networks where the failure of one node can cascade across regions. The 2003 Northeast Blackout, which affected 55 million people in the U.S. and Canada, began with a software bug in an Ohio energy company’s system that failed to alert operators to overgrown trees touching power lines.
The sequence of events leading to system failure included:
- Failure of alarm systems
- Lack of real-time monitoring
- Inadequate communication between regional operators
Today, smart grids use AI and predictive analytics to prevent such failures, but they introduce new risks—like cyberattacks.
Water Treatment System Failures
Contaminated water supplies due to system failure can lead to public health crises. In 2014, Flint, Michigan, experienced a water crisis when cost-cutting measures led to improper treatment of river water, causing lead to leach into the supply.
Root causes included:
- Corrosion control protocols ignored
- Lack of oversight and accountability
- Failure to test water quality regularly
This was not just a technical failure, but a systemic one involving policy, governance, and public trust.
Digital System Failure: When the Internet Goes Down
In our hyper-connected world, digital system failure can be as disruptive as a natural disaster. From cloud outages to DNS collapses, the internet’s fragility is often underestimated.
Cloud Service Outages and Their Ripple Effects
Cloud platforms like AWS, Google Cloud, and Microsoft Azure host millions of websites and applications. When one fails, the impact is global. In December 2021, an AWS outage disrupted Netflix, Slack, and Disney+, affecting users worldwide.
The root cause? A configuration change in the network’s routing system that overloaded critical components.
- Single points of failure in cloud architecture
- Over-reliance on centralized providers
- Limited visibility into backend operations for customers
Experts recommend multi-cloud strategies and better failover mechanisms to mitigate such risks.
DNS Failures and Domain System Collapse
The Domain Name System (DNS) is the internet’s phonebook. If it fails, websites become unreachable—even if the servers are running. In 2016, a massive DDoS attack on Dyn, a major DNS provider, took down Twitter, Spotify, and GitHub.
The attack exploited millions of insecure IoT devices, turning them into a botnet. This highlighted a critical vulnerability: the internet’s reliance on a few key DNS providers.
- Lack of DNS redundancy
- Vulnerability of IoT devices to malware
- Slow response to large-scale cyberattacks
System Failure in Aviation and Transportation
In aviation, system failure can mean the difference between life and death. Aircraft are among the most redundant and rigorously tested systems, yet failures still occur—often due to a chain of small errors.
Aircraft System Failures: Redundancy vs. Reality
Modern aircraft like the Boeing 787 or Airbus A350 have triple-redundant systems for flight controls, navigation, and communication. Despite this, system failure can still happen.
The 2018 and 2019 crashes of Boeing 737 MAX planes were linked to the MCAS (Maneuvering Characteristics Augmentation System), which relied on a single sensor. When that sensor failed, the system forced the plane into a dive.
- Over-reliance on automation without proper safeguards
- Inadequate pilot training for new systems
- Regulatory oversight failures
This tragedy underscored the danger of designing systems that assume perfect conditions.
Autonomous Vehicle System Failures
Self-driving cars rely on sensors, AI, and real-time data processing. A system failure in any of these components can lead to accidents. In 2018, an Uber autonomous vehicle struck and killed a pedestrian in Arizona. The system failed to recognize the person as a human, and the safety driver was distracted.
Key issues in autonomous system failure:
- Sensor misinterpretation (e.g., confusing plastic bags with solid objects)
- AI decision-making under edge cases
- Lack of standardized testing protocols
As AI becomes more integrated, ensuring fail-safe mechanisms is paramount.
Financial System Failure: When Markets Collapse
Financial systems are perhaps the most complex and interconnected of all. A system failure here can trigger global recessions, wipe out savings, and destabilize governments.
The 2008 Global Financial Crisis: A Systemic Breakdown
The 2008 crisis was not caused by a single event but by a perfect storm of risky lending, poor regulation, and complex financial instruments like mortgage-backed securities.
When housing prices dropped, defaults surged, and the system failure cascaded from subprime lenders to global banks. Lehman Brothers collapsed, AIG needed a bailout, and millions lost homes and jobs.
- Over-leveraging by financial institutions
- Rating agencies giving false confidence
- Lack of transparency in derivatives markets
This was a textbook case of systemic risk—where the whole system is vulnerable because of interdependencies.
Algorithmic Trading and Flash Crashes
In 2010, the U.S. stock market experienced a “flash crash” where the Dow Jones dropped nearly 1,000 points in minutes before recovering. The cause? A single large sell order executed by an algorithm, which triggered a cascade of automated responses.
Algorithmic trading now accounts for over 60% of market volume. While efficient, it introduces new risks:
- Speed amplifies errors
- Lack of human intervention in critical moments
- “Ghost algorithms” that continue trading after being decommissioned
Regulators have since introduced circuit breakers, but the threat of digital system failure in finance remains high.
Preventing System Failure: Strategies and Best Practices
While we can’t eliminate all risks, we can build more resilient systems. Prevention requires a combination of technology, process, and culture.
Redundancy and Fail-Safe Design
The most effective way to prevent system failure is to design for it. Redundancy means having backup components that take over when the primary one fails.
Examples include:
- Duplicate servers in data centers
- Secondary flight control systems in aircraft
- Emergency power generators in hospitals
However, redundancy alone isn’t enough. Systems must also have fail-safe modes—like a nuclear reactor’s SCRAM system that shuts down immediately upon detection of anomalies.
Regular Maintenance and System Audits
Preventive maintenance is crucial. The British Airways outage could have been avoided with better hardware monitoring and scheduled replacements.
Best practices include:
- Scheduled system health checks
- Automated monitoring tools
- Log analysis to detect early warning signs
Organizations should adopt frameworks like ITIL (Information Technology Infrastructure Library) to standardize maintenance processes.
Human Training and Crisis Simulation
Even the best technology fails without skilled humans to manage it. Regular training and simulation drills prepare teams for real-world system failure scenarios.
For example, air traffic controllers undergo regular emergency simulations. Hospitals run “code black” drills for IT outages. Financial firms test disaster recovery plans quarterly.
- Cross-training employees to handle multiple roles
- Conducting post-mortems after every incident
- Encouraging a culture of reporting near-misses
Case Studies: Real-World Examples of System Failure
Learning from past mistakes is essential. These case studies highlight how system failure unfolds and what lessons can be drawn.
Case Study 1: The Therac-25 Radiation Therapy Machine
In the 1980s, the Therac-25, a medical device used for radiation therapy, delivered lethal doses of radiation to patients due to a software race condition. Six known accidents occurred, resulting in deaths and severe injuries.
The root cause? A lack of hardware interlocks and over-reliance on software for safety. The system assumed no errors would occur, and when they did, there was no backup.
- Software was reused from older models without proper testing
- Error messages were vague (e.g., “MALFUNCTION 54”)
- No independent safety checks were in place
This case is now a staple in software engineering ethics courses.
Case Study 2: The Fukushima Daiichi Nuclear Disaster
In 2011, a tsunami disabled the power supply and cooling systems at Japan’s Fukushima nuclear plant, leading to meltdowns in three reactors. This was a cascading system failure triggered by a natural disaster but worsened by design flaws.
Key failures included:
- Backup generators located in flood-prone areas
- Inadequate emergency response planning
- Poor communication between TEPCO and regulators
The disaster led to global re-evaluation of nuclear safety standards.
Case Study 3: Facebook’s 2021 Global Outage
In October 2021, Facebook, Instagram, WhatsApp, and Oculus went offline for nearly six hours. The cause? A BGP (Border Gateway Protocol) misconfiguration that withdrew Facebook’s DNS routes from the internet.
Because internal tools also relied on the same network, engineers couldn’t remotely fix the issue and had to physically access servers.
- Over-centralization of network control
- Lack of isolated administrative access
- Insufficient testing of configuration changes
The incident cost the company an estimated $60 million in lost revenue and damaged trust.
Emerging Threats: AI, Cybersecurity, and Climate Change
As technology evolves, so do the risks of system failure. New frontiers like artificial intelligence, quantum computing, and climate change introduce unprecedented challenges.
AI-Induced System Failure
AI systems can fail in unpredictable ways. In 2016, Microsoft’s chatbot Tay was corrupted by malicious users within 24 hours, turning it into a racist, conspiracy-pushing bot.
More concerning are “black box” AI models where even developers don’t fully understand decision-making processes. If an AI controlling a power grid or medical device fails, diagnosing the cause becomes extremely difficult.
- Bias in training data leading to flawed decisions
- Adversarial attacks manipulating AI inputs
- Lack of explainability in deep learning models
Cyberattacks as a Catalyst for System Failure
Ransomware attacks on hospitals, power plants, and government agencies are no longer hypothetical. In 2021, the Colonial Pipeline shutdown caused fuel shortages across the U.S. East Coast after a ransomware attack encrypted critical systems.
Cyberattacks exploit vulnerabilities in both technology and human behavior. Phishing, zero-day exploits, and supply chain attacks can all trigger system failure.
- Insufficient endpoint protection
- Delayed patching of known vulnerabilities
- Third-party vendor risks
Organizations must adopt zero-trust security models and conduct regular penetration testing.
Climate Change and Infrastructure Stress
Rising temperatures, extreme weather, and sea-level rise are stressing infrastructure beyond design limits. In 2021, Texas’ power grid failed during a winter storm because equipment wasn’t winterized, despite previous warnings.
Climate-related system failures will become more common unless infrastructure is adapted. This includes:
- Hardening power lines against storms
- Upgrading drainage systems for heavier rainfall
- Relocating critical facilities from flood zones
What is the most common cause of system failure?
The most common cause of system failure is human error, often compounded by poor design, lack of training, or inadequate procedures. While technology plays a role, most major failures trace back to decisions—or oversights—made by people.
How can organizations prevent system failure?
Organizations can prevent system failure by implementing redundancy, conducting regular maintenance, training staff, performing system audits, and simulating crisis scenarios. A proactive culture of risk assessment and continuous improvement is essential.
What is a cascading system failure?
A cascading system failure occurs when the failure of one component triggers a chain reaction that causes other components to fail. This is common in power grids, computer networks, and financial systems where interdependencies amplify the initial problem.
Can AI prevent system failure?
Yes, AI can help prevent system failure by predicting equipment breakdowns, detecting anomalies in real time, and optimizing system performance. However, AI itself can also be a source of failure if not properly designed, tested, and monitored.
What was the biggest system failure in history?
One of the biggest system failures in history was the 2003 Northeast Blackout, which affected 55 million people. However, the 2008 global financial crisis could be considered the most impactful, as it triggered a worldwide recession and long-term economic damage.
System failure is not just a technical issue—it’s a human, organizational, and societal challenge. From power grids to financial markets, from healthcare to transportation, the systems we rely on are only as strong as their weakest link. While we can’t predict every failure, we can design for resilience, prepare for the worst, and learn from past mistakes. The key is to stop viewing system failure as an anomaly and start treating it as an inevitable risk that must be managed. By embracing redundancy, investing in training, and adopting proactive monitoring, we can build systems that don’t just survive—but thrive—in the face of adversity.
Further Reading: